
История хакерских методов
В этом разделе мы собираемся не просто поговорить об истории хакерства, а рассмотреть ее с различных точек зрения. Прошлые события и факты получили широкую огласку; существует множество ресурсов, в которых описаны эти события и их участники. Поэтому мы не будем повторяться, а познакомимся с эволюцией хакерских методов. Вы увидите, что многих случаев успешного взлома можно было избежать при правильной настройке системы и использовании программных методов.
Коллективный доступ
Первоначальной целью при создании интернета был общий доступ к данным и совместная работа исследовательских институтов. Таким образом, большинство систем было сконфигурировано для коллективного использования информации. При работе в операционной системе Unix использовалась сетевая файловая система (Network File System, NFS), которая позволяла одному компьютеру подключать диск другого компьютера через локальную сеть (local area network, LAN) или интернет.
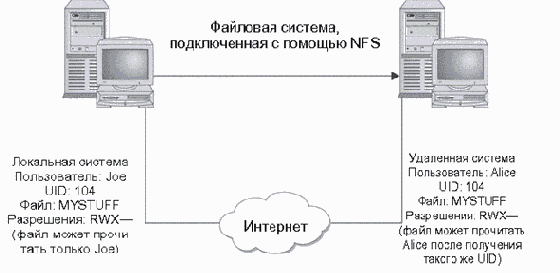
Этим механизмом воспользовались первые хакеры для получения доступа к информации - они подключали удаленный диск и считывали ее. NFS использовала номера идентификаторов пользователя (user ID, UID) в качестве промежуточного звена для доступа к данным на диске. Если пользователь JOE с номером ID 104 имел разрешение на доступ к файлу на своем домашнем компьютере, то другой пользователь ALICE с номером ID 104 на удаленном компьютере также мог прочитать этот файл. Опасность возросла, когда некоторые системы разрешили общий доступ в корневую файловую систему (root file system), включая файлы конфигурации и паролей. В этом случае хакер мог завладеть правами администратора и подключить корневую файловую систему, что позволяло ему изменять файлы конфигурации удаленной системы (рис. 3.1).
Общий доступ к файлам нельзя считать уязвимым местом, это, скорее, серьезная ошибка конфигурации. Самое интересное, что многие операционные системы (включая ОС Sun) поставляются с корневой файловой системой, экспортируемой для общедоступного чтения/записи. Следовательно, любой пользователь на любом компьютере, связавшись с Sun-системой, может подключать корневую файловую систему и вносить в нее произвольные модификации.
Если не изменить заданную по умолчанию конфигурацию системы, то это может сделать каждый, кто захочет.
увеличить изображение
Рис. 3.1. Использование сетевой файловой системы NFS для доступа к удаленным системным файлам
Совет
В большинстве случаев совместный доступ к файлам контролируется настройкой правил на внешнем межсетевом экране организации (см. в лекции 10). В тех системах, где это не сделано, еще не поздно с помощью межсетевого экрана наложить ограничения на общий доступ.
Уязвимое место в виде совместного доступа к файлам имеется не только в операционной системе Unix, но и в Windows NT, 95, 98. Некоторые из этих систем можно настроить на разрешение удаленного подключения к их файловым системам. Если пользователь решит установить совместный доступ к файлам, то он по ошибке может легко открыть свою файловую систему для всеобщего использования.
Внимание!
Новые системы коллективного доступа к файлам, например Gnutella, позволяют компьютерам внутренней сети устанавливать общий доступ к файлам других систем в интернете. Эти системы имеют перенастраиваемую конфигурацию и могут открывать порты, обычно защищенные межсетевым экраном (например, порт 80). Такие системы представляют более серьезную опасность, чем NFS и общий доступ к файлам в ОС Windows.
В ту же самую категорию, что и совместное использование файлов и неправильная настройка, относится удаленный доступ с доверительными отношениями. Использование службы удаленного входа в систему без пароля rlogin является обычным делом среди системных администраторов и пользователей. Rlogin позволяет пользователям входить сразу в несколько систем без повторного ввода пароля. Этими разрешениями управляют файлы типа .rhost и host. В случае правильной настройки (хотя мы считаем, что использование rlogin недопустимо вообще) они однозначно определяют те системы, для которых разрешен удаленный вход. Система Unix использует знак "плюс" ("+"), размещенный в конце файла, который означает, что отдельные системы доверяют пользователю, что ему не обязательно повторно вводить пароль, и не важно, с какой системы он входит.
Естественно, хакеры любят находить такие ошибки. Все, что им нужно сделать для проникновения в систему - это идентифицировать учетную запись пользователя или администратора.
Примечание
Межсетевые экраны могут контролировать не только коллективное использование файлов, но и удаленный доверительный доступ из внешней сети. Однако во внутренней сети внешний межсетевой экран такой контроль выполнить не сможет. И это является серьезной проблемой безопасности.
Слабые пароли
Наверное, самый общий способ, который используют хакеры для входа в систему, - это слабые пароли. Пароли по-прежнему применяются для аутентификации пользователей. Так как это стандартный метод идентификации для большинства систем, он не связан с дополнительными расходами. Кроме того, пользователи понимают, как работать с паролями. К сожалению, многие не знают, как выбрать сильный пароль. Очень часто используются короткие пароли (меньше четырех символов) или легко угадываемые. Короткий пароль позволяет применить атаку "в лоб", т. е. хакер будет перебирать предположительные пароли, пока не подберет нужный. Если пароль имеет длину два символа (и это буквы), то возможных комбинаций будет всего 676. При восьмисимвольном пароле (включающем только буквы) число комбинаций увеличивается до 208 миллионов. Естественно, гораздо легче угадать двухсимвольный пароль, чем восьмисимвольный!
Легко угадываемый пароль также является слабым паролем. Например, пароль корневого каталога "toor" ("root", записанный в обратном порядке) позволит хакеру очень быстро получить доступ к системе. Некоторые проблемы, связанные с паролем, принадлежат к категории неправильной настройки системы. Например, в старейшей корпорации цифрового оборудования Digital Equipment Corporation систем VAX/VMS учетная запись службы эксплуатации (field service) имела имя "field" и заданный по умолчанию пароль "field". Если системный администратор не знал об этом и не менял пароль, то любой мог получить доступ к системе с помощью данной учетной записи.
Вот несколько слабых паролей: wizard, NCC1701, gandalf и Drwho.
Наглядный пример того, как слабые пароли помогают взламывать системы, - червь Морриса. В 1988 г. студент Корнеллского университета Роберт Моррис разработал программу, которая распространялась через интернет. Эта программа использовала несколько уязвимых мест для получения доступа к компьютерным системам и воспроизведения самой себя. Одним из уязвимых мест были слабые пароли. Программа наряду со списком наиболее распространенных паролей использовала следующие пароли: пустой пароль, имя учетной записи, добавленное к самому себе, имя пользователя, фамилию пользователя и зарезервированное имя учетной записи. Этот червь нанес ущерб достаточно большому количеству систем и весьма эффективно вывел из строя интернет.
Вопрос к эксперту
Вопрос. Существует ли надежная альтернатива паролям?
Ответ. Альтернативой паролям являются смарт-карты (маркеры аутентификации) и биометрия. Однако развертывание таких систем связано с дополнительными расходами. Кроме того, их можно использовать не всегда. Например, онлайновый продавец вряд ли воспользуется ими для аутентификации своих покупателей. Так что, скорее всего, пароли останутся с нами в обозримом будущем.
Совет
Не существует универсальных решений проблемы паролей. В большинстве операционных систем системный администратор имеет возможность настраивать требования к паролям, и это очень важно. Однако лучшая защита от слабых паролей - обучение служащих должному пониманию проблем безопасности.
Эта функция сначала была включена в Sendmail как инструмент для отладки программы. Подобные функции, оставленные в программах общего назначения, позволяют хакерам моментально проникать в системы, использующие эти программы. Хакеры идентифицировали множество таких лазеек, большинство из которых было, в свою очередь, устранено программистами. К сожалению, некоторые "черные ходы" существуют до сих пор, поскольку не на всех системах обновилось программное обеспечение.
Не так давно бум в программировании веб-сайтов привел к созданию новой категории "неосторожного" программирования. Она имеет отношение к онлайновой торговле. На некоторых веб-сайтах информация о покупках: номер товара, количество и даже цена - сохраняется непосредственно в строке адреса URL. Эта информация используется веб-сайтом, когда вы подсчитываете стоимость покупок и определяете, сколько денег снято с вашей кредитной карты. Оказывается, что многие сайты не проверяют информацию при упорядочивании списка, а просто берут ее из строки URL. Если хакер модифицирует URL перед подтверждением, он сможет получить пустой номер в списке. Бывали случаи, когда хакер устанавливал цену с отрицательным значением и, вместо того чтобы потратить деньги на покупку, получал от веб-сайта кредит. Не совсем разумно оставлять подобную информацию в строке адреса, которая может быть изменена клиентом, и не проверять введенную информацию на сервере. Несмотря на то, что это уязвимое место не позволяет хакеру войти в систему, большому риску подвергается и веб-сайт, и организация.
Социальный инжиниринг
Социальный инжиниринг - это получение несанкционированного доступа к информации или к системе без применения технических средств. Вместо использования уязвимых мест или эсплойтов хакер играет на человеческих слабостях. Самое сильное оружие хакера в этом случае - приятный голос и актерские способности. Хакер может позвонить по телефону сотруднику компании под видом службы технической поддержки и узнать его пароль "для решения небольшой проблемы в компьютерной системе сотрудника".
В большинстве случаев этот номер проходит.
Иногда хакер под видом служащего компании звонит в службу технической поддержки. Если ему известно имя служащего, то он говорит, что забыл свой пароль, и в результате либо узнает пароль, либо меняет его на нужный. Учитывая, что служба технической поддержки ориентирована на безотлагательное оказание помощи, вероятность получения хакером хотя бы одной учетной записи весьма велика.
Хакер не поленится сделать множество звонков, чтобы как следует изучить свою цель. Он начнет с того, что узнает имена руководителей на веб-сайте компании. С помощью этих данных он попытается раздобыть имена других служащих. Эти новые имена пригодятся ему в разговоре со службой технической поддержки для получения информации об учетных записях и о процедуре предоставления доступа. Еще один телефонный звонок поможет узнать, какая система используется и как осуществляется удаленный вход в систему. Используя имена реальных служащих и руководителей, хакер придумает целую историю о важном совещании на сайте клиента, на которое он якобы не может попасть со своей учетной записью удаленного доступа. Сотрудник службы технической поддержки сопоставит факты: человек знает, что происходит, знает имя руководителя и компании - и, недолго думая, предоставит ему доступ.
Другими формами социального инжиниринга являются исследование мусора организаций, виртуальных мусорных корзин, использование источников открытой информации (веб-сайтов, отчетов, предоставляемых в Комиссию по ценным бумагам США, рекламы), открытый грабеж и самозванство. Кража портативного компьютера или набора инструментов сослужит хорошую службу хакеру, который захочет побольше узнать о компании. Инструменты помогут ему сыграть роль обслуживающего персонала или сотрудника компании.
Социальный инжиниринг позволяет осуществить самые хитроумные проникновения, но требует времени и таланта. Он обычно используется хакерами, которые наметили своей жертвой конкретную организацию.
Совет
Самой лучшей обороной против атак социального инжиниринга является информирование служащих.
Объясните им, каким образом служба технической поддержки может вступать с ними в контакт и какие вопросы задавать. Объясните персоналу этой службы, как идентифицировать сотрудника, прежде чем говорить ему пароль. Расскажите персоналу организации о выявлении людей, которые не должны находиться в офисе, и о том, как поступать в этой ситуации.
Переполнение буфера
Переполнение буфера - это одна из ошибок программирования, используемая хакерами (см. следующий раздел). Переполнение буфера труднее обнаружить, чем слабые пароли или ошибки конфигурации. Однако требуется совсем немного опыта для его эксплуатации. К сожалению, взломщики, отыскавшие возможности переполнения буфера, публикуют свои результаты, включая в них сценарий эксплойта или программу, которую может запустить каждый, кто имеет компьютер.
Переполнение буфера особенно опасно тем, что позволяет хакерам выполнить практически любую команду в системе, являющейся целью атаки. Большинство сценариев переполнения буфера дают хакерам возможность создания новых способов проникновения в атакуемую систему. С недавнего времени вход в систему посредством переполнения буфера заключался в добавлении строки в файл inetd.conf (в системе Unix этот файл управляет службами telnet и FTP), которая создает новую службу для порта 1524 (блокировка входа). Эта служба позволяет злоумышленнику запустить интерпретатор команд root shell.
Следует отметить, что переполнение буфера не ограничивает доступ к удаленной системе. Существует несколько типов переполнений буфера, с помощью которых можно повысить уровень пользователя в системе. Локальные уязвимые места так же опасны (если не больше), как и удаленные.
Что такое переполнение буфера
Переполнение буфера - это попытка разместить слишком много данных в области компьютерной памяти. Например, если мы создадим переменную длиной в восемь байтов и запишем в нее девять байтов, то девятый байт разместится в памяти сразу вслед за восьмым. Если мы попробуем поместить еще больше данных в эту переменную, то в конечном итоге заполнится вся память, используемая операционной системой.
В случае переполнения буфера интересуемая нас часть памяти называется стеком и является возвращаемым адресом функции, исполняемой на следующем шаге.
Стек управляет переключением между программами и сообщает операционной системе, какой код выполнять, когда одна часть программы (или функции) завершает свою задачу. В стеке хранятся локальные переменные функции. При атаке на переполнение буфера хакер помещает инструкции в локальную переменную, которая сохраняется в стеке. Эти данные занимают в локальной переменной больше места, чем выделенный под нее объем, и переписывают возвращаемый адрес в точку этой новой инструкции (рис. 3.2). Эта новая инструкция загружает для выполнения программную оболочку (осуществляющую интерактивный доступ) или другое приложение, изменяет файл конфигурации (inetd.conf) и разрешает хакеру доступ посредством создания новой конфигурации.
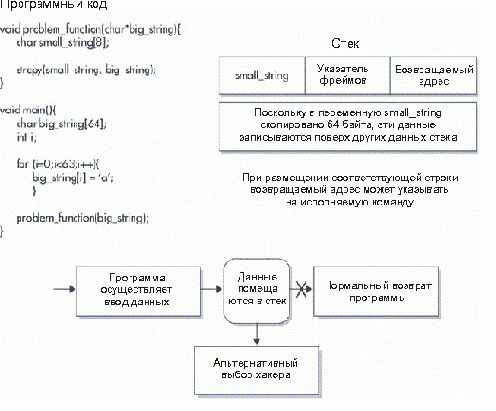
Рис. 3.2. Так работает переполнение буфера
Почему возникает переполнение буфера?
Переполнение буфера происходит очень часто из-за ошибки в приложении, когда пользовательские данные копируются в одну и ту же переменную без проверки объема этих данных перед выполнением операции. Очень многие программы страдают этим. Однако данная проблема устраняется довольно быстро, сразу, как только выявляется и привлекает к себя внимание разработчика. Но если это так легко сделать, то почему переполнение буфера существует до сих пор? Если программист будет проверять размер пользовательских данных перед их размещением в предварительно объявленной переменной, то переполнения буфера можно будет избежать.
Примечание
Следует заметить, что многие общие функции копирования строк в языке программирования С не выполняют проверку размера строки или буфера перед копированием данных. К ним относятся функции strcat(), strcpy(), sprintf(), vsprintf(), scanf() и gets().
Переполнение буфера можно обнаружить в результате исследования исходного кода программ. Хотя это звучит просто, на самом деле процесс долгий и сложный. Намного легче помнить о переполнении буфера в процессе создания программы, чем потом возвращаться и искать его.
Совет
Существует несколько автоматизированных сценариев, используемых для поиска вероятного переполнения буфера. К таким программным средствам относится программа SPLINT (http://lclint.cs.virginia.edu/), которая производит проверку кода перед его компиляцией.
Отказ в обслуживании
Атаки на отказ в обслуживании (Denial-of-service, DoS) - это злонамеренные действия, выполняемые для запрещения легальному пользователю доступа к системе, сети, приложению или информации. Атаки DoS имеют много форм, они бывают централизованными (запущенными от одной системы) или распределенными (запущенными от нескольких систем).
Атаки DoS нельзя полностью предотвратить, их нельзя и остановить, если не удастся выявить источник нападения. Атаки DoS происходят не только в киберпространстве. Пара кусачек является нехитрым инструментом для DoS-атаки - надо только взять их и перерезать кабель локальной сети. В нашем рассказе мы не будем останавливаться на физических атаках DoS, а обратим особое внимание на атаки, направленные против компьютерных систем или сетей. Вы просто должны запомнить, что физические атаки существуют и бывают довольно разрушительны, иногда даже в большей степени, чем атаки в киберпространстве.
Следует отметить еще один важный момент в подготовке большинства атак. Пока взломщику не удастся проникнуть в целевую систему, DoS-атаки запускаются с подложных адресов. IP-протокол имеет ошибку в схеме адресации: он не проверяет адрес отправителя при создании пакета. Таким образом, хакер получает возможность изменить адрес отправителя пакета для скрытия своего расположения. Большинству DoS-атак для достижения нужного результата не требуется возвращение трафика в домашнюю систему хакера
Централизованные DoS-атаки
Первыми типами DoS-атак были централизованные атаки (single-source), т. е. для осуществления атаки использовалась одна-единственная система. Наиболее широкую известность получила так называемая синхронная атака (SYN flood attack) (рис. 3.3). При ее выполнении система-отправитель посылает огромное количество TCP SYN-пакетов (пакетов с синхронизирующими символами) к системе-получателю.
SYN- пакеты используются для открытия новых TCP-соединений. При получении SYN-пакета система-получатель отвечает ACK-пакетом, уведомляющим об успешном приеме данных, и посылает данные для установки соединения к отправителю SYN-пакета. При этом система-получатель помещает информацию о новом соединении в буфер очереди соединений. В реальном TCP-соединении отправитель после получения SYN ACK-пакета должен отправить заключительный АСК-пакет. Однако в этой атаке отправитель игнорирует SYN ACK-пакет и продолжает отправку SYN-пакетов. В конечном итоге буфер очереди соединений на системе-получателе переполняется, и система перестает отвечать на новые запросы на подключение.
Очевидно, что если источник синхронной атаки имеет легальный IP-адрес, то его можно относительно легко идентифицировать и остановить атаку. А если адрес отправителя является немаршрутизируемым, таким как 192.168.х.х? Тогда задача усложняется. В случае продуманного выполнения синхронной атаки и при отсутствии должной защиты IP-адрес атакующего практически невозможно определить.
Для защиты систем от синхронных атак было предложено несколько решений. Самый простой способ - размещение таймера во всех соединениях, ожидающих очереди. По истечении некоторого времени соединения должны закрываться. Однако для предотвращения грамотно подготовленной атаки таймер придется установить равным такому маленькому значению, что это сделает работу с системой практически невозможной. С помощью некоторых сетевых устройств можно выявлять и блокировать синхронные атаки, но эти системы склонны к ошибочным результатам, поскольку ищут определенное количество отложенных подключений в заданном промежутке времени. Если атака имеет несколько источников одновременно, то ее очень трудно идентифицировать.
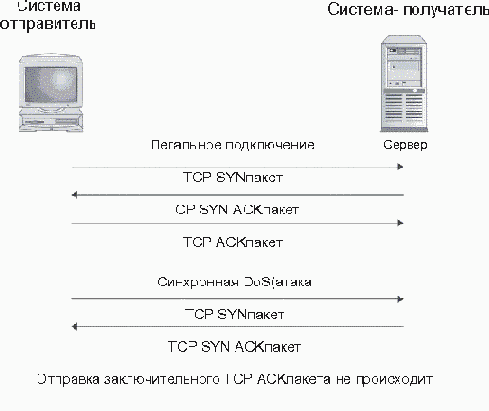
Рис. 3.3. Синхронная DoS-атака
После синхронной атаки были выявлены и другие атаки, более серьезные, но менее сложные в предотвращении. При выполнении атаки "пинг смерти" (Ping of Death) в целевую систему отправлялся пинг-пакет (ICMP эхо-запрос).
В обычном варианте пинг- пакет не содержит данных. Пакет "пинг смерти" содержал большое количество данных. При чтении этих данных системой-получателем происходило переполнение буфера в стеке протоколов, и возникал полный отказ системы. Разработчики стека не предполагали, что пинг-пакет будет использоваться подобным образом, и поэтому проверка количества данных, помещаемых в маленький буфер, не выполнялась. Проблема была быстро исправлена после выявления, и в настоящее время осталось мало систем, уязвимых для этой атаки.
"Пинг смерти" - лишь одна разновидность DoS-атаки, нацеленная на уязвимые места систем или приложений и являющаяся причиной их остановки. DoS-атаки разрушительны лишь в начальной стадии и быстро теряют свою силу после исправления системных ошибок.
Примечание
К сожалению, выявление новых DoS-атак, направленных против приложений и операционных систем, носит регулярный характер. От новых нападений можно немного отдохнуть, лишь пока хакеры исправляют ошибки в сценариях прошлых атак.
Распределенные DoS-атаки
Распределенные DoS-атаки (Distributed DoS attacks, DDoS) - это DoS-атаки, в осуществлении которых участвует большое количество систем. Обычно DDoS-атакой управляет одна главная система и один хакер. Эти атаки не обязательно бывают сложными. Например, хакер отправляет пинг-пакеты по широковещательным адресам большой сети, в то время как с помощью подмены адреса отправителя - спуфинга (spoofing) - все ответы адресуются к системе-жертве (рис. 3.4). Такая атака получила название smurf-атаки. Если промежуточная сеть содержит много компьютеров, то количество ответных пакетов, направленных к целевой системе, будет таким большим, что приведет к выходу из строя соединения из-за огромного объема передаваемых данных.
Современные DDoS-атаки стали более изощренными по сравнению со smurf-атакой. Новые инструментальные средства атак, такие как Trinoo, Tribal Flood Network, Mstream и Stacheldraht, позволяют хакеру координировать усилия многих систем в DDoS-атаке, направленной против одной цели.
Эти средства имеют трехзвенную структуру. Хакер взаимодействует с главной системой или серверным процессом, размещенным на системе-жертве. Главная система взаимодействует с подчиненными системами или клиентскими процессами, установленными на других захваченных системах. Подчиненные системы ("зомби") реально осуществляют атаку против целевой системы (рис. 3.5). Команды, передаваемые к главной системе и от главной системы к подчиненным, могут шифроваться или передаваться с помощью протоколов UDP (пользовательский протокол данных) или ICMP (протокол управляющих сообщений), в зависимости от используемого инструмента. Действующим механизмом атаки является переполнение UDP-пакетами, пакетами TCP SYN или трафиком ICMP. Некоторые инструментальные средства случайным образом меняют адреса отправителя атакующих пакетов, чрезвычайно затрудняя их обнаружение.
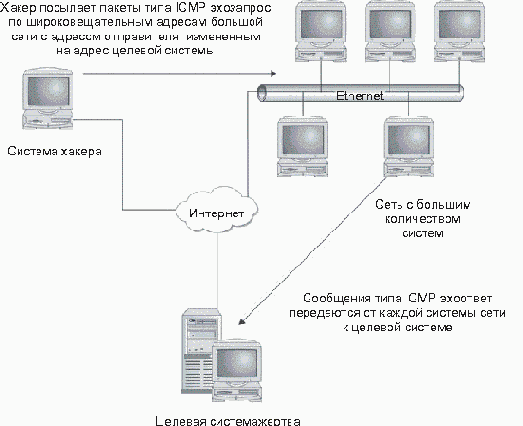
Рис. 3.4. Осуществление smurf-атаки
Главным результатом DDoS-атак, выполняемых с использованием специальных инструментов, является координация большого количества систем в атаке, направленной против одной системы. Независимо от того, сколько систем подключено к интернету, сколько систем используется для регулирования трафика, такие атаки могут буквально сокрушить организацию, если в них участвует достаточное количество подчиненных систем.
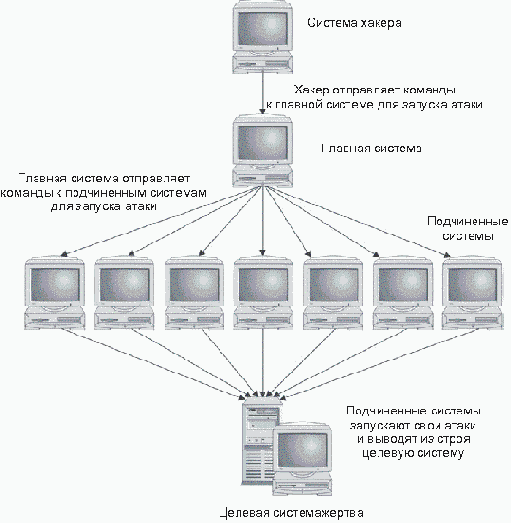
Рис. 3.5. Структура инструментального средства для выполнения DDoS-атаки